Assignment 2
Introduction
For this assignment, you will be implementing Structure from Motion.
- Feature Matching
- Structure from Motion
We have made available a visualization tool using the Three.js library implemented in "./js/assignment2.js" and an example implementation located in "./assignments/assignment2.py". Your objective is to fill in TODOs in the python files and make modification based on it. You are encouraged to use a programming language with which you are comfortable. The output results should be in the ply format, and you must visualize your outcomes accordingly.
How to Submit: Please submit this template file along with your implementation as a zip file. The zip file should contain your source code, the generated results in PLY mesh format, and a report that has been modified using this HTML file. The report should comprise your results and a concise explanation of your implementation. Alternatively, you may choose to create a GitHub repository containing all these elements and provide a link for submission.
Requirements / Rubric: The grading is based on the correctness of your implementation. You are encouraged to use the visualization tool to debug your implementation. You can also use the visualization tool to test your implementation on other 3D models.
- +80 pts: Implement the structure-from-motion algorithm with the start code.
- +20 pts: Write up your project, algorithms, reporting results (reprojection error) and visualisations, compare your reconstruction with open source software Colmap.
- +10 pts: Extra credit (see below)
- -5*n pts: Lose 5 points for every time (after the first) you do not follow the instructions for the hand in format
Extract Credit: You are free to complete any extra credit:
- up to 5 pts: Present results with your own captured data.
- up to 10 pts: Implement Bundle Adjustment in incremental SFM.
- up to 10 pts: Implement multi-view stereo (dense reconstruction).
- up to 20 pts: Create mobile apps to turn your SFM to a scanner.
- up to 10 pts: Any extra efforts you build on top of basic SFM.
Structure From Motion
Outline of the Implementation
This assignment on structure from motion requires the completion of the three TODOs left in the code. The
basic outline of the structure from motion pipeline is in the SFM class. The pipeline goes as follows:
- Step 0 (Feature Matching)
- Feature extraction (SIFT) followed by matching (BFMatcher/Flann based matcher) is done previously and
saved serialized into file that are used further down the pipeline.
- Step 1 (Baseline Pose Estimation)
- The pipeline begins by estimating the pose/transformation (rotation and translation) of the first
two images in the dataset. This is done using fundamental matrix and essential matrix methods.
- Step 2 (Baseline Triangulation)
- Once the poses of the first two images are estimated, the pipeline performs triangulation to
reconstruct 3D points from matched feature points between these images. This concludes the
initialization step of the view.
- Step 3 (First Point Cloud Generation)
- A point cloud is generated after triangulating matched feature points.
This forms the initial structure of the scene.
- Step 4 (Pose Estimation and Triangulation for the remaining Images)
- The pipeline iterates over the remaining images, estimating poses, triangulating new points,
updating the 3D point cloud, and evaluating reprojection errors for each image. The steps are:
- Get pose (implementation provided)
- Get features (implementation provided)
- Find matches (implementation provided)
- Remove outliers (implemented using fundamental matrix method)
- Triangulate and merge the point clouds (similar to triangulating new view but only
using the inliers)
After every round of triangulation, reprojection error is also calculated to quantify the
performance of the estimation. images are also plotted to visualize the differences on a few
samples. The three TODOs are all associated with calculating the reprojection error, visualizing and
implementing triangulation in step 5. above. please refer to the
sfm.py file for the exact implementation.
Results
In this section, I present the results from the algorithm for various datasets.
Although the testing has been done across many datasets here I will be using only the following:
fountain-P11 and Herz-Jesus-P8. The full dataset is available
here.
Reprojection Error
I use different parameters for outlier detection for different subjects. outlier_thres which is
internally mapped to ransacReprojThreshold when computing the fundamental matrix is different for
different datasets. The values are: 0.9 for fountain-P11 and 0.4 for Herz-Jesus-P8.
| fountain-P11 |
Herz-Jesus-P8 |
| Image Name |
Reprojection Error |
Image Name |
Reprojection Error |
| 0000 |
0.478 |
0000 |
0.182 |
| 0001 |
0.491 |
0001 |
0.224 |
| 0002 |
0.596 |
0002 |
0.832 |
| 0003 |
0.362 |
0003 |
0.905 |
| 0004 |
2.720 |
0004 |
5.986 |
| 0005 |
1.930 |
0005 |
12.256 |
| 0006 |
4.127 |
0006 |
9.549 |
| 0007 |
8.172 |
0007 |
16.798 |
| 0008 |
11.433 |
-- |
-- |
| 0009 |
9.627 |
-- |
-- |
| 0010 |
11.928 |
-- |
-- |
| Mean Error: 4.715 |
Mean Error: 5.841 |
| Time Taken: 2.568s |
Time Taken: 1.4s |
Reprojection Point Error Estimates
Here are some camera pose estimates from selected images from the datasets. The full output is saved in the
assets directory.
| fountain-P11 |
Herz-Jesus-P8 |
| Image Name |
Image |
Image Name |
Image |
| 0000 |
 |
0000 |
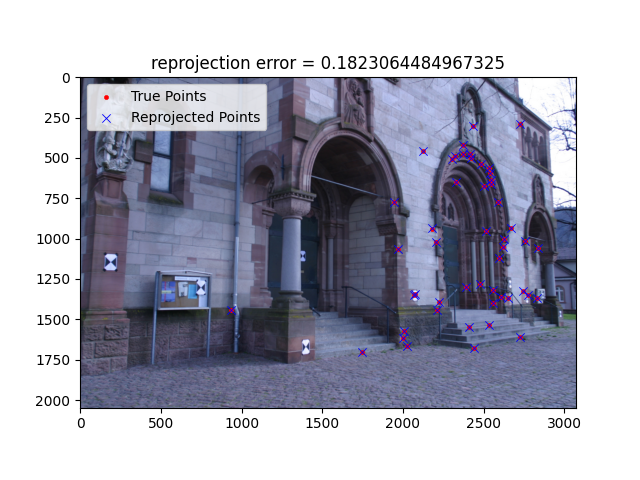 |
| 0005 |
 |
0004 |
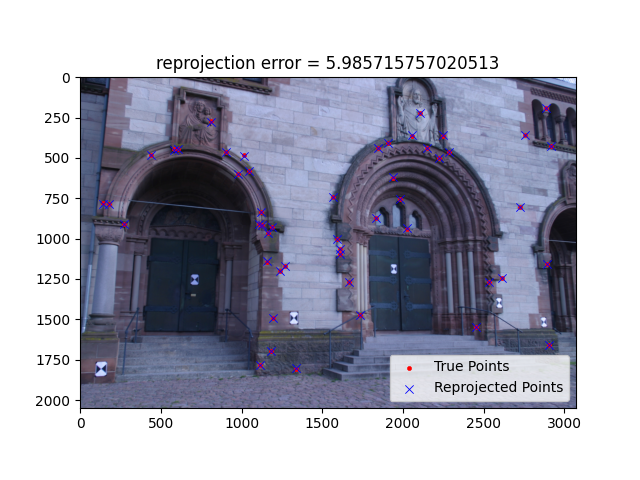 |
| 0010 |
 |
0007 |
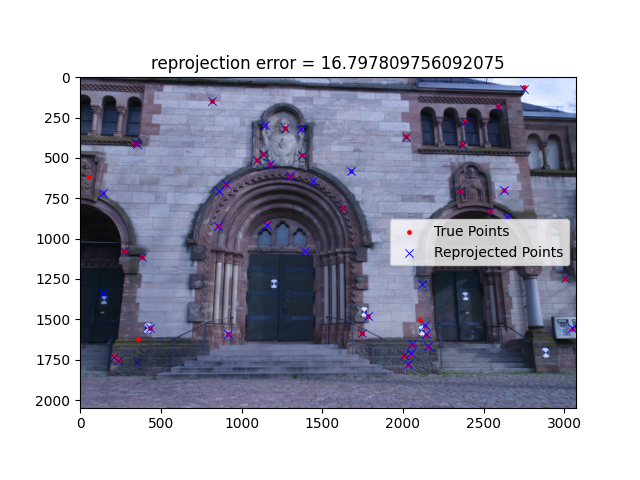 |
Point Cloud Visualization (and Comparison with Colmap)
Results from my implementation:
| fountain-P11 |
Herz-Jesus-P8 |
| View Number |
Point Cloud |
View Number |
Point Cloud |
| cloud_2_view |
|
cloud_2_view |
|
| cloud_7_view |
|
cloud_5_view |
|
| cloud_11_view |
|
cloud_8_view |
|
Running the two datasets in colmap generate the following point clouds. These point clouds are more richer and
accurate to the image dataset provided.
| fountain-P11 (Colmap) |
Herz-Jesus-P8 (Colmap) |
| Final Point Cloud |
|
|
Extra Credit
I collected my own dataset for this experiment. It can be found
here.
The images need to be first exported to a png or jpg format. I also had to update the code in several places to
make this work. Such as changing the matcher to be a flann based matcher and changes the parameters for
the matcher and fundamental matrix calculation to make this work.
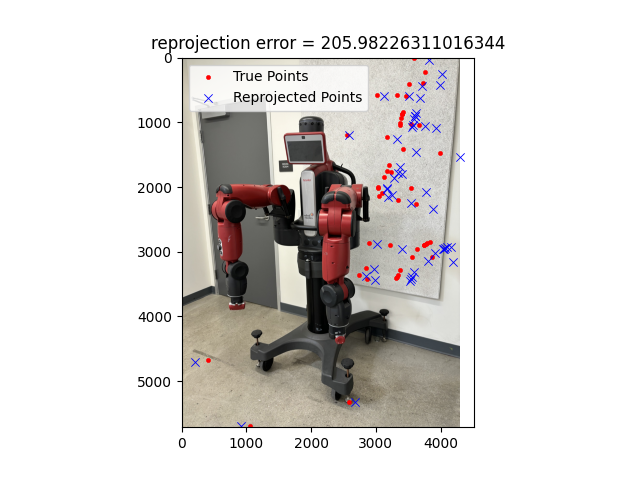
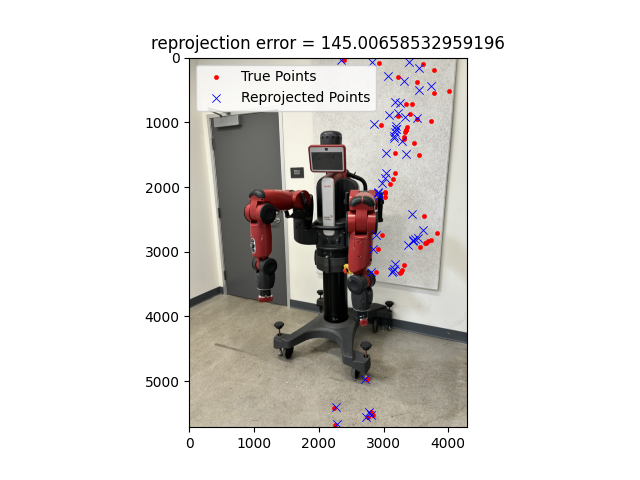
Here is a a visualization of the camera reprojection error:
As you can see the error is quite poor and the pointclouds are not coherent. The problem in this case lies first
with feature detection as none of them lie on the baxter robot. Secondly, I think bundle adjustment could
prove very useful here to make the process more accurate.