For this assignment, you will be training your own NeRF or Gaussian Splatting.
We have made available a visualization tool using the Three.js library implemented in "./js/assignment3.js" and an example NerfStudio Colab can be found here. You have the option to launch the demo either through Colab or on your local machine. It is important to note that while Colab offers free TPU access, completing the training within the free tier may not be feasible. In this assignment, your task is to collect your own data, conduct calibration, and train your NeRF/3DGS model. You are welcome to use any programming language you are comfortable with. Ensure that the final results are exported in obj/ply format for visualization. You should then evaluate your results by comparing them with solutions from Mesh Room or COLMAP.| Metric | Value |
| PSNR (Peak Signal to Noise Ratio) | 25.66154670715332 |
| PSNR (Peak Signal to Noise Ratio) Std | 1.937759518623352 |
| SSIM (Structural Similarity Index Measure) | 0.8653780221939087 |
| SSIM (Structural Similarity Index Measure) Std | 0.03032178431749344 |
| LPIPS (Learned Perceptual Image Patch Similarity) | 0.09439089894294739 |
| LPIPS (Learned Perceptual Image Patch Similarity) Std | 0.013973996974527836 |
| Render Performance Metrics | |
| Num Rays Per Sec | 727773.875 |
| Num Rays Per Sec Std | 37743.16015625 |
| Frames Per Sec | 1.403884768486023 |
| Frames Per Sec Std | 0.07280702888965607 |
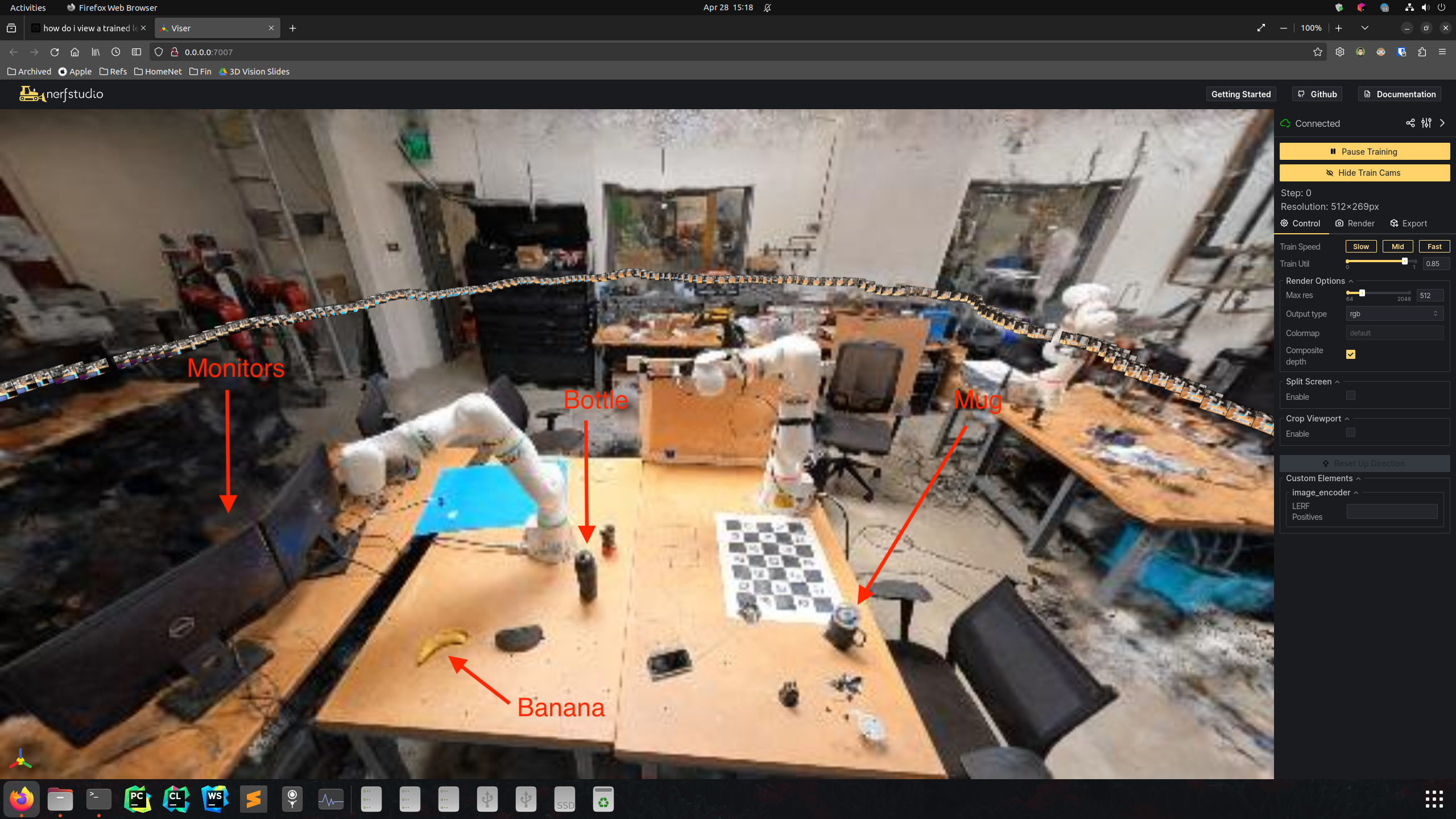
| Scene in RGB | |
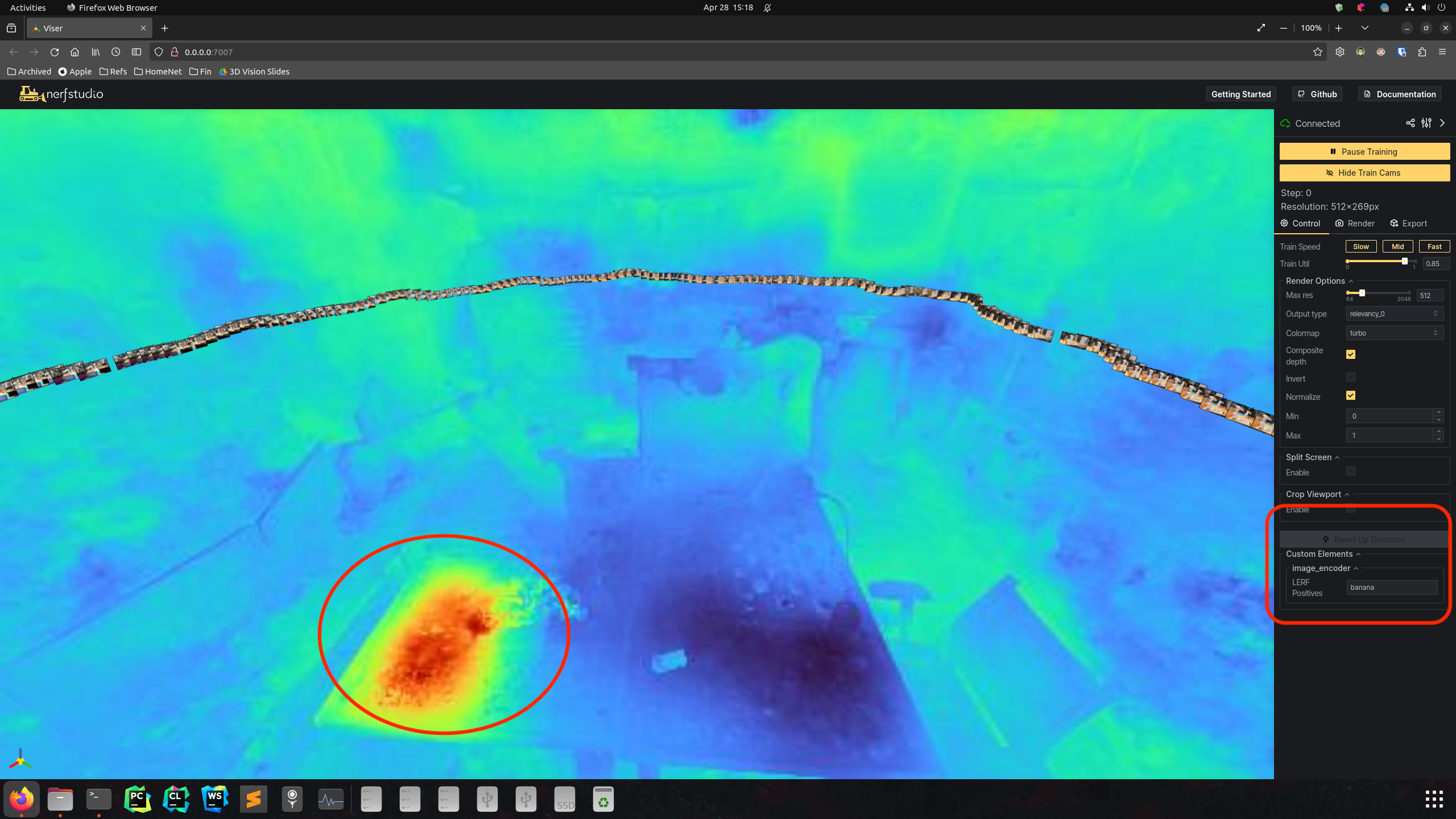
| Relevancy map of Banana | |
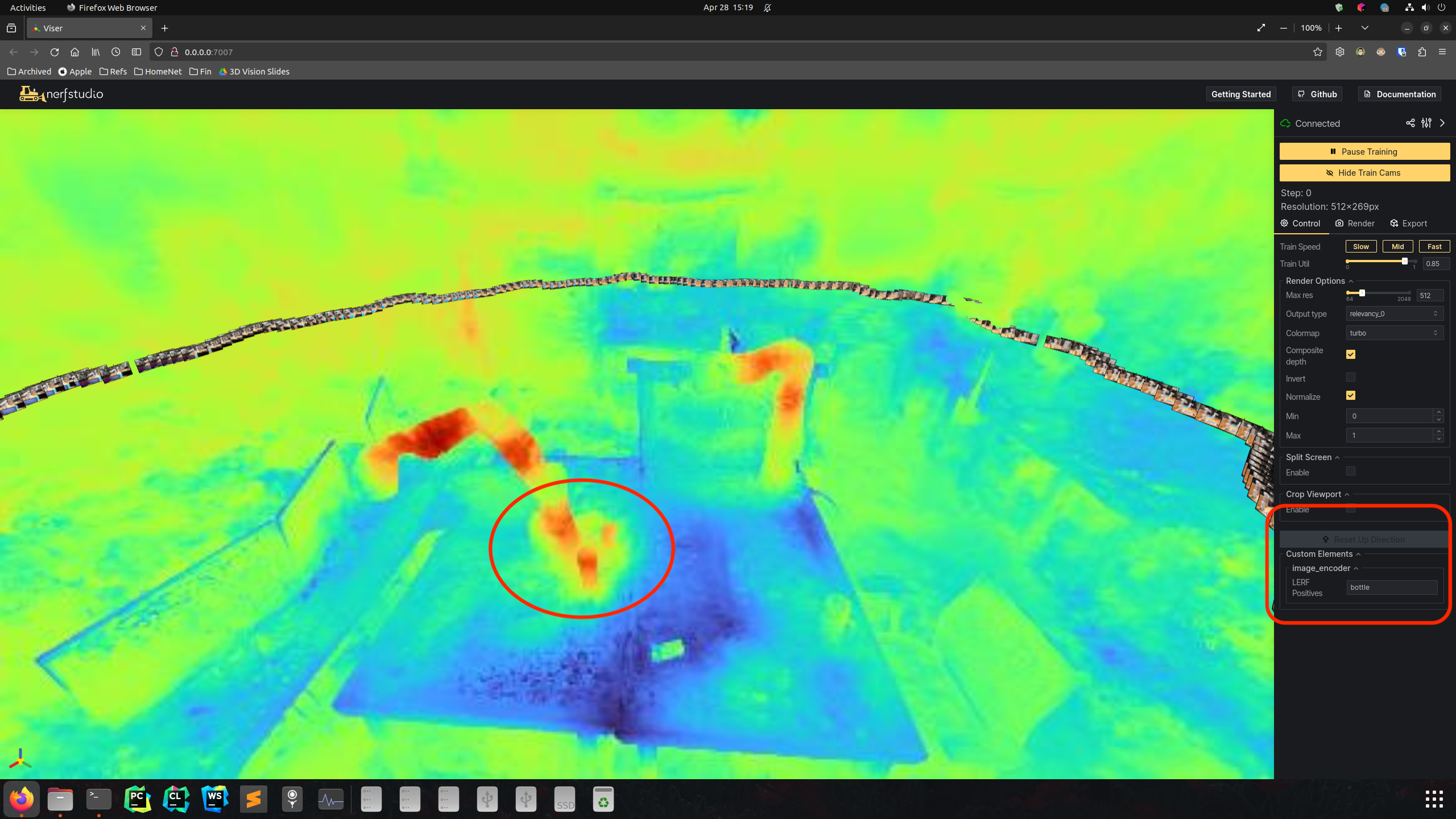
| Relevancy map of Bottle | |
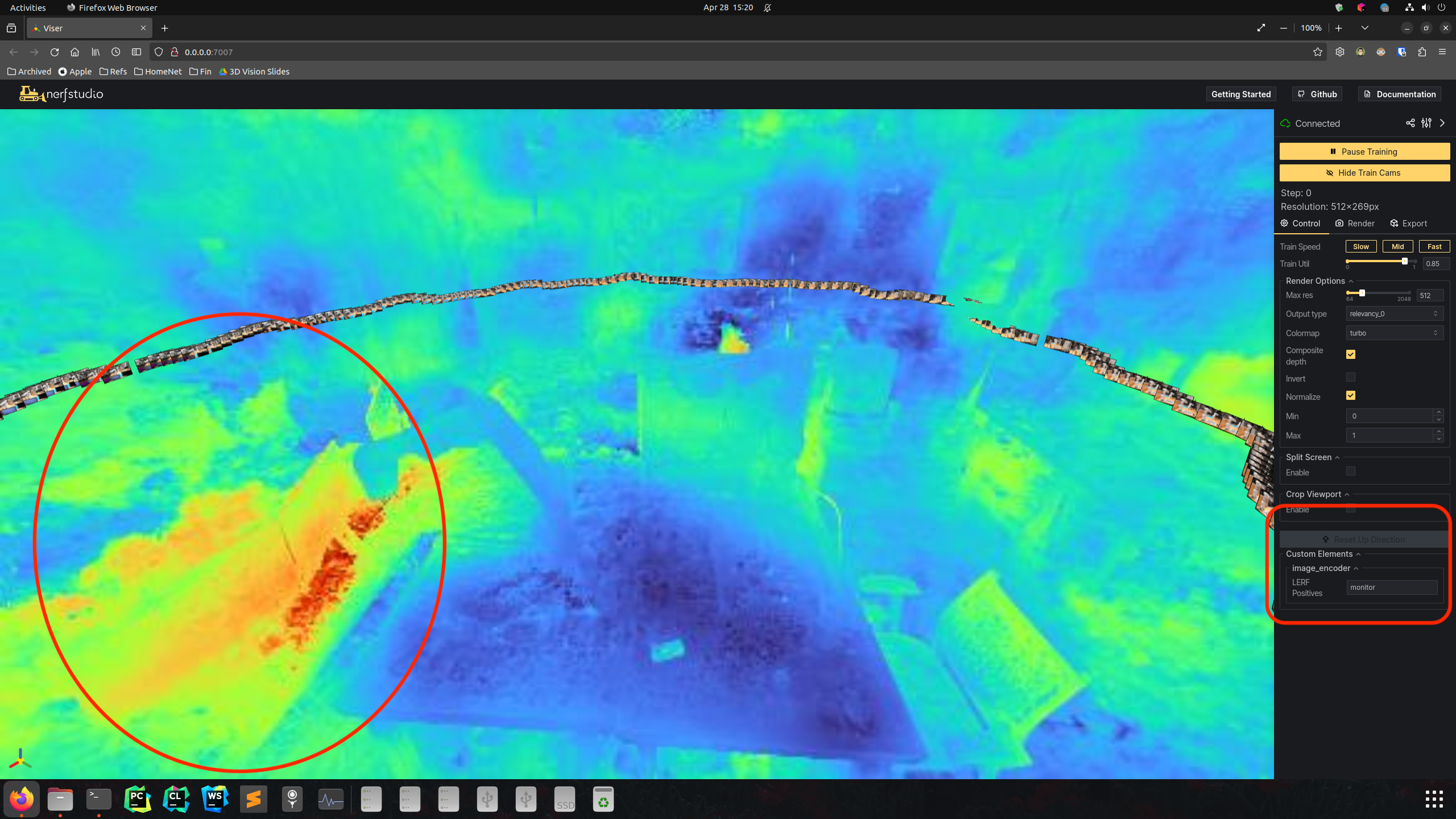
| Relevancy map of Monitor | |
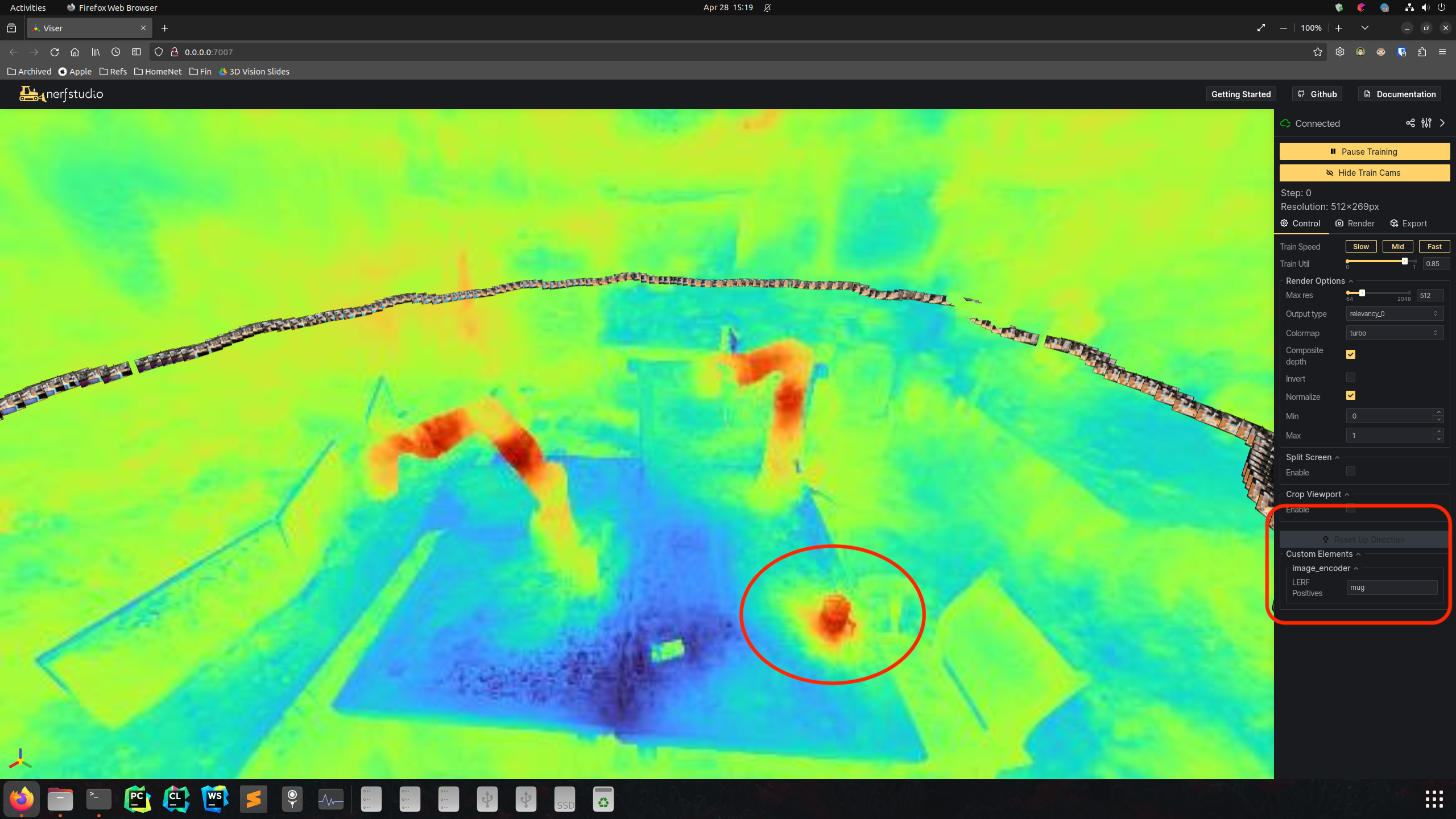
| Relevancy map of Mug | |